Implement fatigue and time-interval-based rules
Note
This feature is only available on the Skedulo Pulse Platform.Overview
Fatigue or time-interval-based rules are a specific type of custom rule. They are typically more complex than other rules, which is why we’ve provided the additional guidance here on how to design and develop them.
This guidance is not intended to be prescriptive; we understand there’s variance in customer needs, so this information should be used to guide your approach and be modified to meet the needs of the solution you’re trying to achieve. This guide is based on the assumption that you already have a base level of custom rule development knowledge. If this is not the case, please read the custom rule documentation before progressing in the design and development of these types of rules.
Types of time-interval-based rules
Examples of fatigue and time-interval-based rules:
-
X number of instances within a period (i.e., 20 jobs within 10 hours)
-
Consecutive number of X type of work within a specific period (such as seven installation jobs in a day)
-
X number of days of consecutive work—irrespective of a specific period or duration (for example seven working days in a row)
-
X number of hours over X duration (i.e., 60 hours in one week)
Sources of rule complexity
Rules that deal with time are inherently complex. The following sections cover specific sources of complexity that can affect how you implement the rules, namely definitions of time, different time zones, and performance requirements.
Definitions of time
Differences in time period definitions and units of time need to be considered, for example:
-
The dynamic and variable nature of defining the windows of time the rules are evaluating. For example, what is a week for the customer; does it align with a calendar week?
-
Defining the start/end times of a single day (to be able to calculate “a day’s work”, you’ll need to define the start and end of a day); does it align with a calendar day? Or does the customer have a differing 24hr period that they consider to be a day? When daylight savings time is in play, for example, a day might be 23 or 25 hours long.
-
Rules based on a rolling time window are generally of higher complexity than other rules—complexity exists in both the implementation of the rule and in optimizing the rule for performance.
-
The evergreen nature of a schedule within the defined windows of time, that is, the summation of hours for each period must be kept up to date.
Different time zones
The complexity of time zone transitions within the days/weeks/months of the period being evaluated need to be considered. For example, if a resource transitions between time zones within a day, the logic will need to determine and then convert the start/end times if required. All times need to be converted to UTC for the Rules service.
Performance requirements
Time-interval-based rules must be implemented in an optimized way. Since rate limiting is in place for system protection, any sub-optimal implementations will result in processing and performance delays for the custom rules and, subsequently, a degraded user experience. Optimizing a rule essentially means that it’s getting, creating, and/or processing data in the most efficient manner.
To help support the need for optimization, we strongly recommend that you implement a custom object that captures the work details for a “day” or “week“. These details could include the start and end time or period, and any rollups or summaries, e.g., total hours. This aids in the efficient implementation and behavior of the custom rules. An example of this is included below.
Note: Time-interval-based rules can be implemented without the use of custom objects and instead directly query the job allocation records on a point-in-time and on-demand basis, but it would likely result in excessive processing power requirements and delays.
Practical example
This example shows the steps required to implement a rule to help meet the following business requirement:
There must be at least 10 hours between the resources’ estimated clock-out times and the next day’s clock-in times.
The steps cover scenario-specific instructions for this use case as well as general guidance that can be applied to similar rule implementations.

Create a custom object
Maintaining the daily clock-in and clock-out times per resource should be part of the solution. In this example, these will be stored in a “Resource Clock Ins” custom object with the following fields:
| Field name | Type | Description |
|---|---|---|
| Resource | Lookup | Link to the Resource object |
| Date | LocalDate | Calendar day |
| Estimated Clock In | Int | Local time in 24-hour format, up to 4 digits, e.g., 600 for 6:00 am |
| Estimated Clock Out | Int | Local time in 24-hour format, up to 4 digits, e.g., 1730 for 5:30 pm |
Note
Resource and Date must be a unique key for the below algorithm to work correctly! See the “Evaluate violations” section below for additional information on how to achieve a unique key for the violation records.
The rule implementation will use data from this table. Using a single time zone in all regions (e.g., Eastern Standard Time, or EST) greatly simplifies the implementation and allows for significant optimizations. In most cases, the clock-in/clock-out times can be maintained simply by using data from the webhook responses—without having to fetch additional data via GraphQL.
Although you can use the time zone relevant to the customer’s location or global region, all violation records must ultimately be passed through to the rules service as in the UTC format.
Configure webhooks for receiving job allocation change events
To maintain the resources’ clock-in data, a webhook must be set up for job allocation changes. Webhooks must be used because they contain information on which fields have changed and what the previous values were (the previous object in the response). This is important information that allows for significant performance optimizations during rule processing.
Note
Triggered actions cannot be used as they don’t contain the object’s previous state.Care must be taken to narrow down the scope of webhooks as much as possible to prevent over-triggering and putting unnecessary load on the rest of the system. Webhooks should only trigger when fields relevant to the processing of the custom rules have changed, e.g., job allocation status, start, end, resourceId, regionId, etc. For maintainability and monitoring reasons, it is recommended to create separate webhooks for each rule.
Don’t forget that fields, such as regionId and resourceId, can be changed on existing violation records. The custom rules should handle these situations as well and should maintain the integrity of the violation records correctly.
Fetch existing clock-in data for the previous, current, and next day
For each callback, fetch the existing clock-in data for the previous, current, and next day.
Because the time zone is fixed, we can figure out the calendar day the event refers to from its start and end UTC timestamps. After this, we need to fetch existing clock-in records for the previous, current, and next days (this should be done in a single GraphQL query).
Process the job allocation event and update clock-in records
Each job allocation event type must be processed differently, as described in the sections that follow.
Job allocation create events
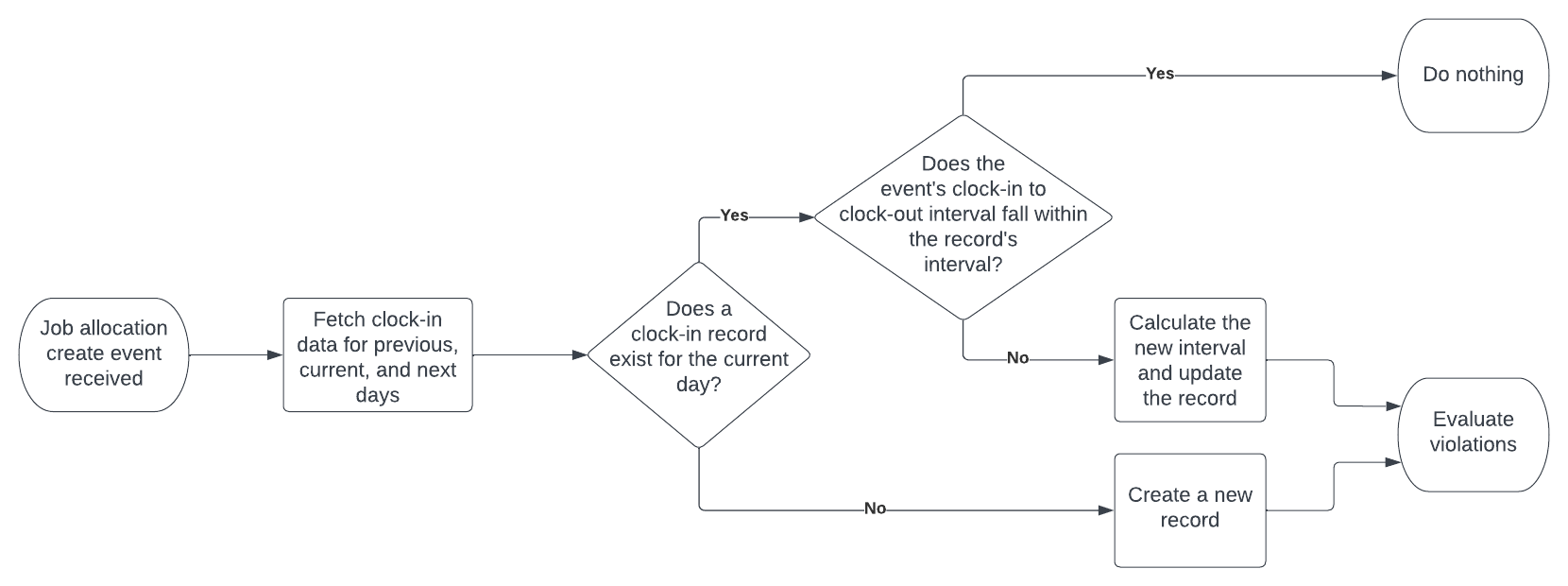
There are a two scenarios that need to be handled:
- If a resource’s clock-in record does not exist for the current day, create a new record for the given day and just store the start and end times in the local time. Then proceed to the “Evaluate violations” step below.
- If a resource’s clock-in record does exist for the current day:
- If the interval defined by the start and end timestamp from the event does not exceed the extent of the interval from the record (so
event.start>=record.startANDevent.end<=record.end), do nothing. Processing stops here. - If the interval exceeds the interval from the record, then calculate the union of the record and event intervals and update the record with the resulting interval value. Proceed to the “Evaluate violations” step below.
- If the interval defined by the start and end timestamp from the event does not exceed the extent of the interval from the record (so
Job allocation update events
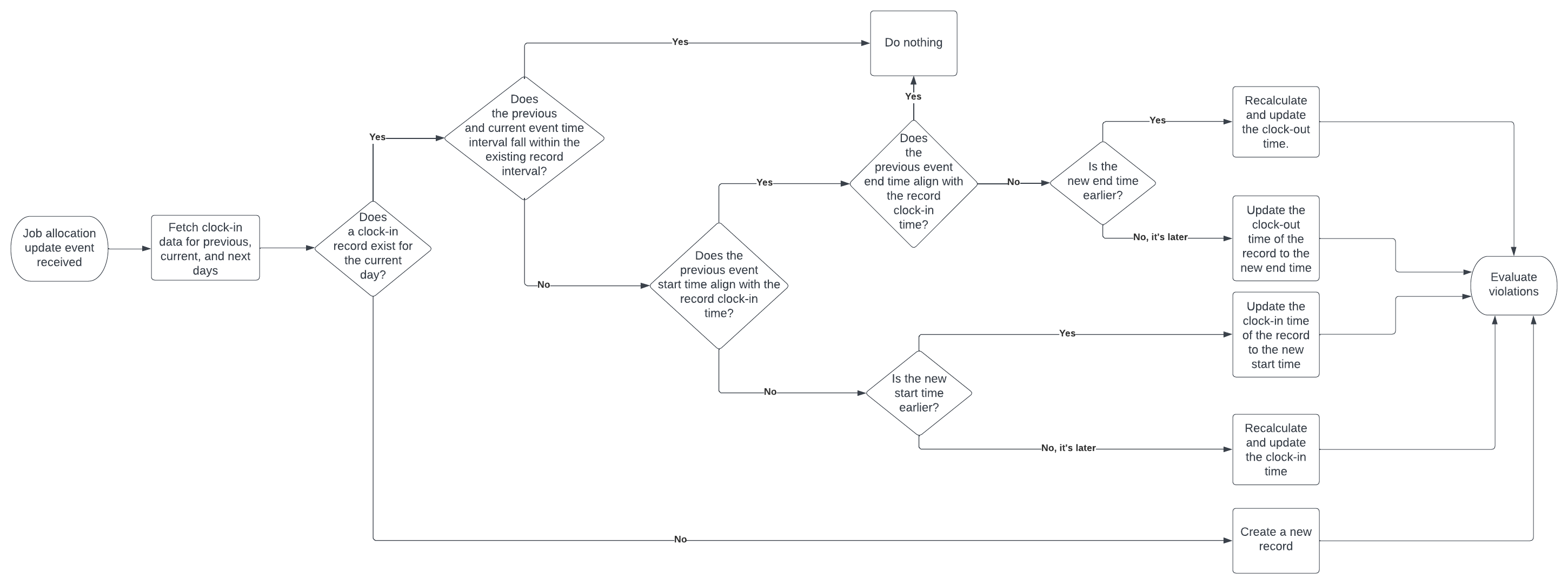
For update events, there are also two main scenarios to handle (the presence or abscence of a record for the current day), however, if there is a record, then additional processing is required depending on how the event’s time data aligns with those of the record.
-
If a resource’s clock-in record does not exist for the current day, create a new record for the given day and just store the start and end times in the local time. Then proceed to the “Evaluate violations” step below.
-
If a record does exist, we’ll potentially need to recalculate the clock-in and clock-out times for the current day from the tenant data with up to two GraphQL queries according to the following scenarios:
-
If both the previous and current job allocation start/end times from the event fall within the clock-in/clock-out interval from the existing record, do nothing. Processing stops here.
-
If the previous start time aligns with the clock-in time from the record, then:
- If the new start time is earlier, update the clock-in time of the record to the new start time.
- If the new start time is later, recalculate and update the clock-in time:
- Fetch the job allocation with the lowest start time within the confines of the day (only fetch a single record: use “LIMIT 1” and “ORDER BY start ASC”).
- If a job allocation was found, update the clock-in field of the existing record with the new start time.
- If no job allocation was found, delete the existing clock-in record. Proceed to the delete path of the “Evaluate violations” step below.
-
If the previous end time aligns with the clock-out time from the record, then:
- If the new end time is later, update the clock-out time of the record to the new end time.
- If the new end time is earlier, recalculate and update the clock-out time:
- Fetch the job allocation with the highest end time within the confines of the day (only fetch a single record: use “LIMIT 1” and “ORDER BY end DESC”).
- If a job allocation was found, update the clock-out field of the existing record with the new end time.
- If no job allocation was found, delete the existing clock-in record. Proceed to the delete path of the “Evaluate violations” step below.
-
This should not normally happen, only if there was a hiccup in maintaining the correct clock-in/clock-out times:
- If either the previous job allocation start is before the clock-in time from the record, or the previous job allocation end is after the clock-out time, perform a full recalculation of both the clock-in and clock-out times as above (we’re in error correction mode here, so it’s best to recalculate everything).
- Proceed to the delete path of the “Evaluate violations” step below.
Job allocation delete events
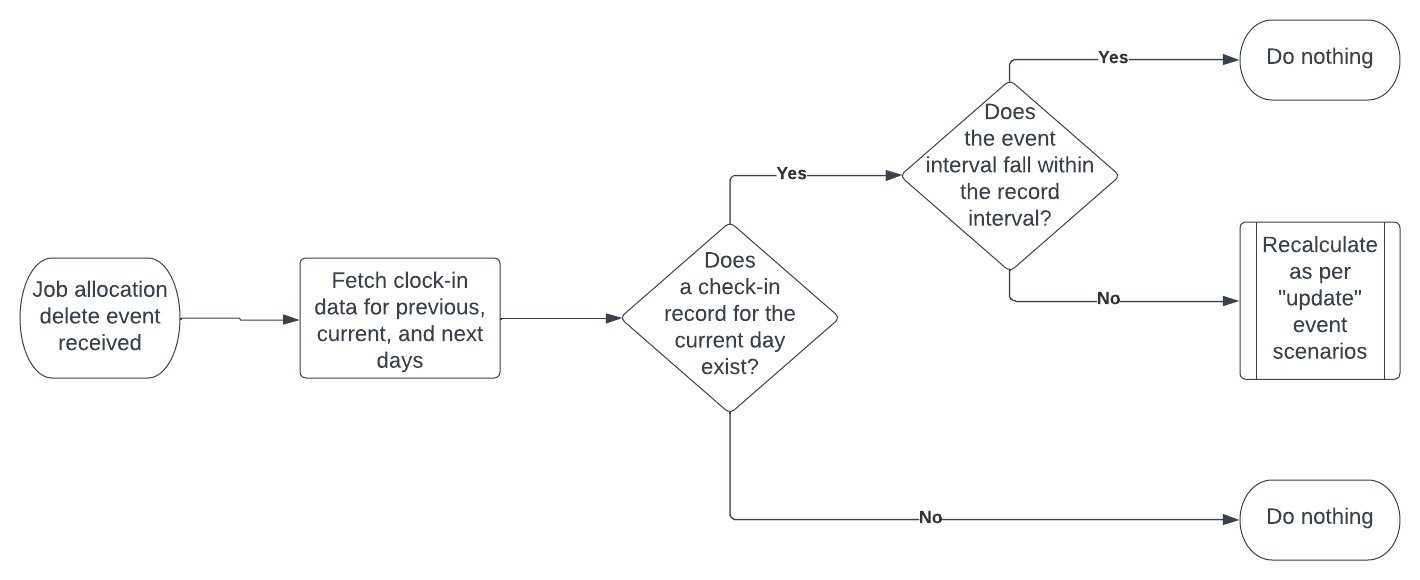
- If no clock-in record exists for the current day, do nothing.
- If a record does exist:
- If the interval defined by the start and end timestamp from the event is fully contained in the interval from the record (so
event.start>record.startANDevent.end<record.end), do nothing. Processing stops here. - Otherwise perform the recalculation described for the
updatecase, then proceed with to the “Evaluate violations” step below.
- If the interval defined by the start and end timestamp from the event is fully contained in the interval from the record (so
Evaluate violations and update violation records
At this point, we have the potentially updated the clock-in records for the current day, and the clock-in records for the previous and next days.
-
If the clock-in time of the current day has been changed (or we had to create a new record), the rule must be evaluated between the previous and the current day.
-
If the difference between the clock-out time of the previous day and the clock-in time of the current day is less than 10 hours, then a violation must be raised (upserted). Otherwise, the potentially existing violation must be deleted.
-
If the clock-out time of the current day has been changed (or we had to create a new record), the rule must be evaluated between the current and the next day.
-
If the difference between the clock-out time of the current day and the clock-in time of the next day is less than 10 hours, a violation must be raised (upserted). Otherwise, the potentially existing violation must be deleted.
In summary, these variations are possible:
-
One clock-in record exists only (for the current day): No need to perform violation evaluation.
-
Two clock-in records exist (for the previous and current, or the current and next days): Perform evaluation and always do a single upsert or delete violation operation.
-
Three clock-in records exist (previous, current, and next days): Perform the evaluation and always do two upsert or delete violation operations.
Ensure violation records have a unique key
The combination of ruleId, targetId, and sourceId fields must uniquely identify rule violation records. This requirement is automatically met for violations that refer to job allocations, since the target ID would be the job ID and the source ID would be the job allocation ID.
Time-interval-based violations that refer to a single resource, however, need to be stored differently. The violation key must be set such that the key’s uniqueness constraints are met whilst still making it possible to create multiple time-interval-based violations of the same type (rule ID) for the same resource (resource ID), but for different time intervals. This can be achieved by doing the following:
-
Set
startTimeandendTimeof the violation record to the time interval the violation refers to in UTC. That is, set it to the start of the first day and the end of the second day (previous day and current day or current day and next day). -
Set
targetIdandsourceIdto any random UUID (this is needed to satisfy the unique key constraints of the violation record). -
Set
targetTypeandsourceTypeto the string“randomUUID”. -
Set
resourceIdsto a single-element array containing the Skedulo resource ID.
See the API documentation for details on the rule violation record fields.
Insert a violation
For more information on how to add a custom rule violation record, see the custom rule documentation.
To add a violation record, do the following steps:
-
Set the violation key as per above.
-
Set the remaining fields as needed (
ruleId,regionId,description,context, etc.). -
Add the violation using the
/rules/violationendpoint.
Delete a violation
-
Figure out the
startTimeandendTimefor the potentially existing violation as per above. -
Use the
/rules/violations/searchAPI endpoint to fetch the potentially existing violation. If a violation was found, useDELETEoperation and/rules/violationendpoint to delete it.
Tips and considerations
Auditing
Care must be taken to avoid deleting and then recreating the same violations over and over during processing. For example, for certain custom rules, it might be simpler to delete all possible violations for a record first to start with a “blank slate”, then raise any new violations.
This solution must be avoided at all costs because it will result in flip-flopping of the violation record in the audit logs (i.e., you’ll see the same violation record being deleted, recreated, deleted, recreated, etc. over and over again, which would render the audit logs next to useless!). In such cases, existing violations must be fetched first for the given target or source ID, then the implementation should only delete those violations that will not be re-upserted by the algorithm.
Upserting is not a problem because it retains the row IDs of existing violations; you can upsert a record any number of times, it won’t negatively affect the audit logs.
Processing delayed webhooks and “inactive” objects
Don’t assume that webhook events will be received in near-realtime. It is possible that the sending of webhooks is backlogged, or that the events arrive with more than usual delay for any number of reasons. It follows that it cannot be assumed that the received events and the corresponding data model changes are happening in lockstep, which has far-reaching consequences.
To be specific, it is possible for two or more data change events to take place and to receive the webhook events for them a bit later, after all changes have already been persisted to the database. Here’s an example:
-
The first event would result in the creation of a violation record (e.g., a job allocation was created for the job), but the second event would make the job inactive by changing its status.
-
The webhook for the first event is received after the change in job status has already happened.
-
If the custom rule contains an optimization to disregard jobs with an inactive status, it would incorrectly not raise a violation for the first event because the status of the job as read from the database now is already inactive.
There are many similar scenarios and all possible data transitions need to be considered carefully when optimizing the rules.
Feedback
Was this page helpful?